January 1st 2019, 12:00:00 pm
更多信息可以到文章内细看,这里只做简要记录。
浏览器如何工作:
浏览器的主要功能:
通过从服务器请求并在浏览器窗口中显示它来显示您选择的Web资源。资源的位置由用户使用URI(统一资源标识符)指定。
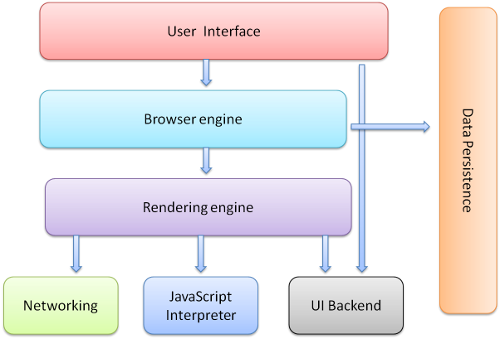
浏览器的主要组件:
- 用户界面
- 浏览器引擎 - 用于查询和操作渲染引擎的界面。
- 渲染引擎 - 负责显示请求的内容。如解析HTML和CSS并在屏幕上显示解析的内容。
- 网络 - 用于网络呼叫,如HTTP请求。它具有平台独立接口和每个平台的底层实现。
- UI后端 - 用于绘制组合框和窗口等基本小部件。它公开了一个非平台特定的通用接口。它下面使用操作系统用户界面方法。
- JavaScript解释器。用于解析和执行JavaScript代码。
- 数据存储。这是一个持久层。浏览器需要保存硬盘上的各种数据,例如cookie。新的HTML规范(HTML5)定义了“web数据库”,它是浏览器中一个完整的(尽管很轻的)数据库。
渲染引擎:
Firefox使用Gecko–一种“自制”Mozilla渲染引擎。Safari和Chrome都使用Webkit。
Webkit是一个开源渲染引擎,起初是Linux平台的引擎,并由Apple修改以支持Mac和Windows。Webkit详细
主要流程:
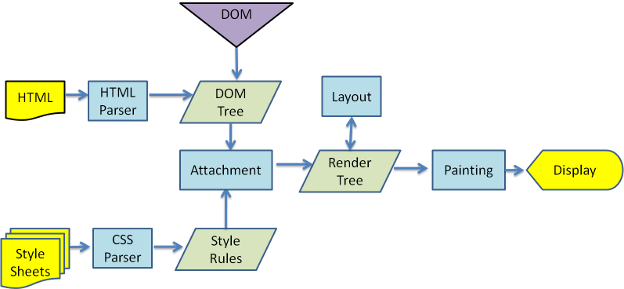
渲染引擎将开始从网络层获取所请求文档的内容。这通常是以8K块的形式完成的。

渲染引擎开始解析HTML文档并将标记转换为名为“内容树”的DOM节点。它解析外部CSS文件和样式元素中的样式数据。样式信息与HTML中的可视指令一起用于创建另一个树 - 渲染树。
渲染树包含具有视觉属性(如颜色和尺寸)的矩形。矩形的顺序正确的在屏幕上显示。
在构建渲染树之后,它将经历“ 布局 ”过程。这意味着为每个节点提供它应该出现在屏幕上的精确坐标。下一个阶段是绘制 - 将遍历渲染树,并使用UI后端层绘制每个节点。
在开始构建和布局渲染树之前,它不会等到解析所有HTML。将解析和显示部分内容,同时继续处理来自网络的其余内容。
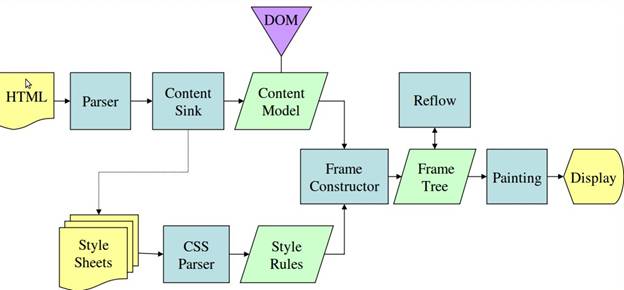
Webkit 流程:
URL 解析器 > HTML 解析器 > CSS 解析器 > JS解析器
解析:
解析器的类型:
- 自上向下解析器:会看到语法的高级结构,并尝试匹配其中一个。
- 自下而上解析器:从输入开始,逐渐将其转换为语法规则,从低级规则开始,直到满足高级规则。
HTML解析器:
HTML不能轻易解析,不能通过传统解析器解析,因为它的语法不是无上下文语法,也不是XML解析器。
HTML解析器的工作是将HTML标记解析为解析树。
HTML定义采用DTD格式。
HTML5规范详细描述了解析算法。该算法包括两个阶段 - 标记化和树形结构。
- 标记化是词法分析,将输入解析为标记。HTML标记包括开始标记,结束标记,属性名称和属性值。
- 标记生成器识别标记,将其提供给树构造函数并使用下一个字符来识别下一个标记,依此类推,直到输入结束。
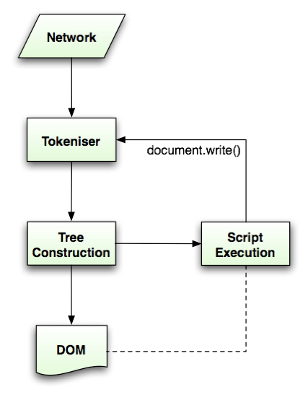
两种算法:The tokenization algorithm(标记化算法) AND Tree construction algorithm.(树构造算法)(没有深入了解)
解析完成后的操作:
在此阶段,浏览器将文档标记为交互式,并开始解析处于“延迟”模式的脚本 - 在解析文档后应执行的脚本。然后将文档状态设置为“完成”,并将触发“加载”事件。
其后还包括CSS解析,DOM解析与布局等,这里都不深入了解了。主要了解渲染流程即可。
编码
编码方式:
url编码:
标准的url结构是:
scheme://login:password@address:port/path?quesry_string#fragment例:http://example.com/test.php?uid=27&content=on#main
平常的URL:像开头的 “ http: “,协议后面跟一个冒号,还有之后的两个正斜杠” // “, 后面再跟域名,再跟地址,再跟参数字符串,再跟片段id…
一些符号非常”常规”,比如冒号,正斜杠,问号…这些都是浏览器/服务器用来解析url用于语义分隔的保留字符,如果出现在url里就会破坏语法,影响正常解析,导致一些问题的发生。
于是就有了url编码,因为有些保留字符可能确实有必要需要在url里出现,它以一个百分号%和该字符的ASCII对应的2位十六进制数去替换这些字符
一些常见的URL字符以及其编码值: 详情 HTML URL 编码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20字符 URL编码值
空格 %20
" %22
# %23
% %25
& %26
( %28
) %29
+ %2B
, %2C
/ %2F
: %3A
; %3B
< %3C
= %3D
> %3E
? %3F
@ %4o
\ %5C
| %7C
html编码:
url的问题类似,为了避免在标签内容中出现以及应对某些攻击,某些保留字符出现在文本节点和标签值里是不安全的,比如说多重标签,xss…等等。于是就有了html编码。
一般以 & 开头,以分号 ; 结尾
1
2
3
4
5
6
7常用HTML编码:
结果 描述 实体名称 实体编号
" quotation mark " "
' apostrophe ' '
& ampersand & &
< less-than < <
> greater-than > >还可以插入以任意十进制ASCII码或Unicode字符编码,样式为:&#数值;
1
2左尖括号 < 写作 <
右尖括号 > 写作 >js编码:
JS解析(\uxxxx)只支持UNICODE。
js常见的反斜杠方式编码处理:
1
2
3
4\b退格符,\t制表符,\v垂直制表符等
3位数字,不足位数用0补充,按8位原字符八进制字符编码,如 \145 代表 e
2位数字,不足位数用0补充,按8位原字符16进制字符编码,前缀 x ,如 \x65 代表 e
4位数字,不足为数用0补充,按16位原字符16进制Unicode数值编码,前缀 u ,如 \u0065 代表 eCSS编码
CSS的属性和值都可以进行CSS编码和解析,冒号:不可以
CSS 解析器并不会等到所有的html都解析完成之后再去构建和布局render树。它是解析完一部分内容就显示一部分内容,同时,可能还在通过网络下载其余内容。
CSS 编码解析是用了一套不太正统的转义策略:用一个反斜杠,后边跟
1~6位十六进制数字构成。,所以字母e 可以编码为 \65, \065,\000065。而因为这样,后边就不能直接紧跟数字或字母,否则会被当成转义里的内容处理,所以CSS 选择了空格作为终止标识,在解码的时候,再将空格去除。
5 .DOM
一个例子。
`document.getElementById("pic1").innerHTML = "";`
如果将pic1也编码的话,也会先解码再添加到HTML里。
DOM 操作实际上是js强势介入HTML和CSS的结果,导致HTML标签的属性和值都可以做JS编码和解析。浏览器解码处理流
浏览器接收时一般不需要对url进行解码处理,只有在发送后,服务器才需要对url进行解码来确定接收参数和定位资源。
HTML
HTML解码是在浏览器构建完DOM树以后才进行解码的
一段HTML例子:
1 | <html> |
当我们把<h1>Main Title</h1>进行编码成:
<h1>Main Title</h1><h1>Main Title</h1>
会发现,第一个没有HTML标签,第二个是正常的。
当解析器对前者(对标签进行html编码)进行解析时,无法识别为html标签,所以构建不了DOM节点,后者不同,于是成功构建了DOM节点。 而在解析器解析完后,就会进行html解码,于是两者都会解码显示。
JS编码:
不管是外部引用还是直接写在script标签里,又或者是在html标签的属性里,对于js编码的解码都是相同的。
一个例子:
1 | <script> |
编码为:
1 | <script> |
js的脚本处理模型是按照 源码处理-函数解析-代码执行这个执行流来的。两种代码都会经过解码再显示出来,所以两种效果都是相同的。
不能用这种方式来替换掉圆括号或引号,会判定为失败。因为对于JavaScript,转义编码应当只出现在标示符部分,不能用于对语法有真正影响的符号。
HTML + CSS
一个例子:
1 | <div id="content"></div> |
script脚本创建了一个属性src=x.com的img标签,并将其作为id=content的div标签的子元素。
script脚本中改变了DOM节点树,最后按照顺序解析,先响应2后响应1,如果把script标签移到img标签之前,结果相反。
浏览器是按一种顺序流执行解析的,html解析完生成DOM树,js解析器会对js编码进行解码,然后对DOM树进行修改,最后修改完的DOM树再进行HTML解码。
可以触发JS解析器的方式:
- 直接嵌入< script> 代码块。
- 通过< script sr=… > 加载代码。
- 各种HTML CSS 参数支持JavaScript:URL 触发调用。
- CSS expression(…) 语法和某些浏览器的XBL 绑定。
- 事件处理器(Event handlers),比如 onload, onerror, onclick等等。
- 定时器,Timer(setTimeout, setInterval)
- eval(…) 调用。
常用的编码表 (From s0md3v)
| HTML | Char | Numeric | Description | Hex | CSS (ISO) | JS (Octal) | URL |
|---|---|---|---|---|---|---|---|
" |
“ | " |
quotation mark | u+0022 | \0022 | \42 | %22 |
# |
# | # |
number sign | u+0023 | \0023 | \43 | %23 |
$ |
$ | $ |
dollar sign | u+0024 | \0024 | \44 | %24 |
% |
% | % |
percent sign | u+0025 | \0025 | \45 | %25 |
& |
`& | & |
ampersand | u+0026 | \0026 | \46 | %26 |
' |
‘ | ' |
apostrophe | u+0027 | \0027 | \47 | %27 |
( |
( | ( |
left parenthesis | u+0028 | \0028 | \50 | %28 |
) |
) | ) |
right parenthesis | u+0029 | \0029 | \51 | %29 |
* |
* | * |
asterisk | u+002A | \002a | \52 | %2A |
+ |
+ | + |
plus sign | u+002B | \002b | \53 | %2B |
, |
, | , |
comma | u+002C | \002c | \54 | %2C |
− |
- | - |
hyphen-minus | u+002D | \002d | \55 | %2D |
. |
. | . |
full stop; period | u+002E | \002e | \56 | %2E |
/ |
/ | / |
solidus; slash | u+002F | \002f | \57 | %2F |
: |
: | : |
colon | u+003A | \003a | \72 | %3A |
; |
;` | ; |
semicolon | u+003B | \003b | \73 | %3B |
< |
< | < |
less-than | u+003C | \003c | \74 | %3C |
= |
= | = |
equals | u+003D | \003d | \75 | %3D |
> |
> | > |
greater-than sign | u+003E | \003e | \76 | %3E |
? |
? | ? |
question mark | u+003F | \003f | \77 | %3F |
@ |
@ | @ |
at sign; commercial at | u+0040 | \0040 | \100 | %40 |
[ |
[ | [ |
left square bracket | u+005B | \005b | \133 | %5B |
\ |
/ | \ |
backslash | u+005C | \005c | \134 | %5C |
] |
] | ] |
right square bracket | u+005D | \005d | \135 | %5D |
^ |
^ | ^ |
circumflex accent | u+005E | \005e | \136 | %5E |
_ |
_ | _ |
low line | u+005F | \005f | \137 | %5F |
` |
` | ` |
grave accent | u+0060 | \0060 | \u0060 | %60 |
{ |
{ | { |
left curly bracket | u+007b | \007b | \173 | %7b |
| |
| | | |
vertical bar | u+007c | \007c | \174 | %7c |
} |
} | } |
right curly bracket | u+007d | \007d | \175 | %7d |
总结:
大多数都是摘抄于其他文章的,自己所写甚少。只作为一个简要笔记用作以后参考。
编码过程是一直都想整理的,也是学习XSS过程中必不可少的环节,这笔记也就算是打下XSS的一点基础了。
XSS的绕过主要是在于以下几个方面(目前的一点拙见):
- 对编码内容的过滤不严格
- 对解码,编码的顺序逻辑出错
- 待补充